安装
系统参数:
- Kube-promethues 版本: 0.10.0
- Kubernetes 版本: v1.20.12
- 项目 Github 地址: https://github.com/prometheus-operator/kube-prometheus/tree/v0.10.0
1、拉取 Prometheus Operator
bash
#从 GitHub 拉取 Prometheus Operator 源码:
wget https://github.com/coreos/kube-prometheus/archive/v0.10.0.tar.gz
#解压:
tar -zxvf kube-prometheus-0.10.0.tar.gz2、文件分类
bash
#由于它的文件都存放在项目源码的 manifests 文件夹下,所以需要进入其中进行启动这些 kubernetes 应用 yaml 文件。又由于这些文件堆放在一起,不利于分类启动,所以这里将它们分类。
#进入源码的 manifests 文件夹:
cd kube-prometheus-0.10.0/manifests/
#创建文件夹
mkdir -p node-Exporter alertmanager grafana kubeStateMetrics prometheus serviceMonitor prometheusAdapter prometheusOperator blackboxExporter prometheusRule
# 移动 yaml 文件,进行分类到各个文件夹下
mv *-serviceMonitor* ./serviceMonitor/
mv grafana-* ./grafana/
mv kubeStateMetrics-* ./kubeStateMetrics/
mv alertmanager-* ./alertmanager/
mv nodeExporter-* ./node-Exporter/
mv prometheusAdapter-* ./prometheusAdapter/
mv prometheus-* ./prometheus/
mv prometheusOperator-* ./prometheusOperator/
mv blackboxExporter-* ./blackboxExporter/
mv *-prometheusRule.yaml prometheusRule/3、修改 Prometheus 持久化
bash
vim prometheus/prometheus-prometheus.yamlyaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.32.1
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
enableFeatures: []
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.32.1
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.32.1
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleNamespaceSelector: {}
ruleSelector: {}
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.32.1
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-client # 改为自己的sc的名字
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi # 根据自己的需求去修改修改持久化的地方
4、修改 Grafana 持久化配置
这里的pvc是新创建的
bash
vim grafana/grafana-pvc.yamlyaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana
namespace: monitoring #---指定namespace为monitoring
spec:
storageClassName: ebs-ssd #---指定StorageClass
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi将 volumes里面的 “grafana-storage” 配置注掉,新增如下配置,挂载一个名为 grafana 的 PVC:
bash
vim grafana/grafana-deployment.yamlbash
- name: grafana-storage # 新增持久化配置
persistentVolumeClaim:
claimName: grafana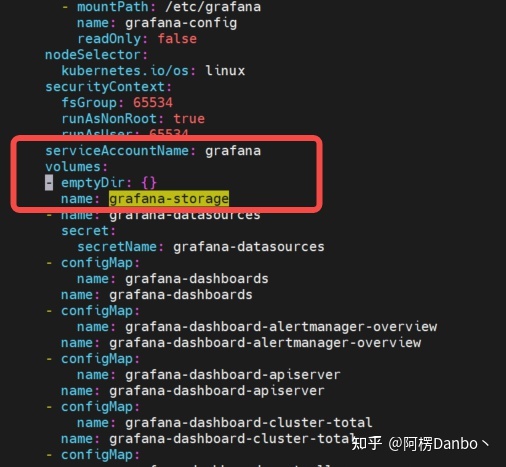
grafana-deployment.yaml 修改前
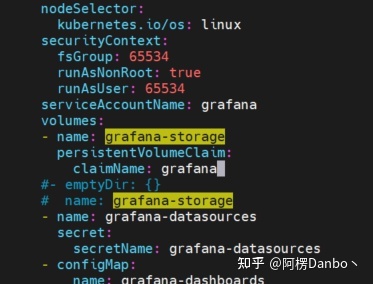
grafana-deployment.yaml 修改后
5、修改Prometheus存储时长
根据自己的需求去修改该值
bash
vi prometheusOperator/prometheusOperator-deployment.yaml
- storage.tsdb.retention.time=30d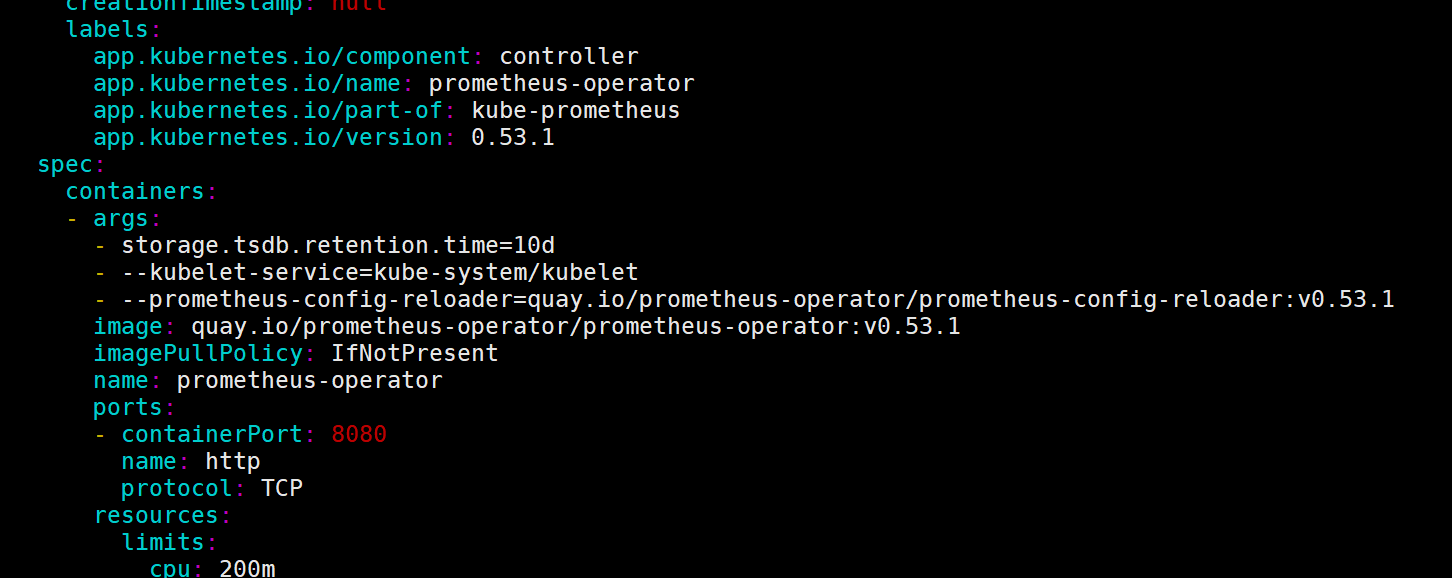
prometheusOperator-deployment.yaml
6、安装Prometheus Operator
bash
kubectl create -f setup/
kubectl get pods -n monitoring
kubectl apply -f alertmanager/
kubectl apply -f blackboxExporter/
kubectl apply -f kubeStateMetrics/
kubectl apply -f node-Exporter/
kubectl apply -f prometheus/
kubectl apply -f prometheusAdapter/
kubectl apply -f prometheusOperator/
kubectl apply -f serviceMonitor/
kubectl apply -f grafana/
kubectl apply -f prometheusRule/查看 Prometheus & Grafana
请在编写的时候注意,prometheus以及grafana的manifest文件中是否有networkPolicy相关的配置,如果有,需要进行相关配置,或者直接删除这个配置,不然无法访问
如果条件不允许可以使用NodePort方式对服务进行暴露
1、配置Prometheus Ingress
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-k8s-ingress
namespace: monitoring
spec:
ingressClassName: nginx
rules:
- host: prometheus-k8s.fsl.com
http:
paths:
- backend:
service:
name: prometheus-k8s
port:
number: 9090
path: /
pathType: Prefix配置域名解析后打开

prometheus 首页

prometheus target
2、配置Grafana Ingress
bash
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana-ingress
namespace: monitoring
spec:
ingressClassName: nginx
rules:
- host: grafana.abcd.xyz
http:
paths:
- backend:
service:
name: grafana
port:
number: 3000
path: /
pathType: Prefix配置域名解析后打开
- 默认用户名:admin
- 默认密码:admin
grafana 首页
grafana dashboard
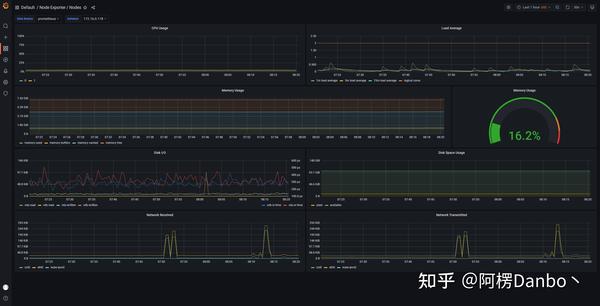
grafana node
模版ID: 13105
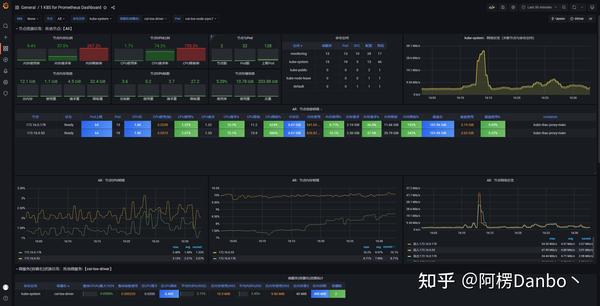
grafana kubernetes
五、小结
安装 Prometheus 之后,我们就可以按照 Metrics 数据的来源,来对 Kubernetes 的监控体系做一个简要的概括:
- 第一种是宿主机(node)的监控数据。这部分数据的提供,需要借助 Node Exporter 。一般来说,Node Exporter 会以 DaemonSet 的方式运行在宿主机上。其实,所谓的 Exporter,就是代替被监控对象来对 Prometheus 暴露出可以被“抓取”的 Metrics 信息的一个辅助进程。而 Node Exporter 可以暴露给 Prometheus 采集的 Metrics 数据, 也不单单是节点的负载(Load)、CPU 、内存、磁盘以及网络这样的常规信息,它的 Metrics 指标很丰富,具体你可以查看 Node Exporter 列表。
- 第二种是来自于 Kubernetes 的 API Server、kubelet 等组件的 /metrics API。除了常规的 CPU、内存的信息外,这部分信息还主要包括了各个组件的核心监控指标。比如,对于 API Server 来说,它就会在 /metrics API 里,暴露出各个 Controller 的工作队列(Work Queue)的长度、请求的 QPS 和延迟数据等等。这些信息,是检查 Kubernetes 本身工作情况的主要依据。
- 第三种是 Kubernetes 相关的监控数据。这部分数据,一般叫作 Kubernetes 核心监控数据(core metrics)。这其中包括了 Pod、Node、容器、Service 等主要 Kubernetes 核心概念的 Metrics。其中,容器相关的 Metrics 主要来自于 kubelet 内置的 cAdvisor 服务。在 kubelet 启动后,cAdvisor 服务也随之启动,而它能够提供的信息,可以细化到每一个容器的 CPU 、文件系统、内存、网络等资源的使用情况。需要注意的是,这里提到的是 Kubernetes 核心监控数据。