prometheus一个重要的概念就是拉取监控信息,简单来说就是,访问一个特定的接口来获取信息,获取的信息是这样的:
tp_response_size_bytes_sum{handler="api"} 8.218998e+06
http_response_size_bytes_count{handler="api"} 8.933263e+06
http_response_size_bytes{handler="prometheus",quantile="0.5"} 3618
http_response_size_bytes{handler="prometheus",quantile="0.9"} 3629
http_response_size_bytes{handler="prometheus",quantile="0.99"} 3634
http_response_size_bytes_sum{handler="prometheus"} 3.5474294e+07
http_response_size_bytes_count{handler="prometheus"} 9943
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 12330.49
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1.048576e+06
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 13
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 1.744896e+07
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.67300021188e+09
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 6.14723584e+08Prometheus 使用 metric 表示监控度量指标,它由 metric name(度量指标名称) 和 labels(标签对) 组成:
<metricname>{<label name=<labelvalue>, ...}metric name 指明了监控度量指标的一般特征,比如 http_requests_total 代表收到的 http 请求的总数。metric name 必须由字母、数字、下划线或者冒号组成。冒号是保留给 recording rules 使用的,不应该被直接使用。
labels 体现了监控度量指标的维度特征,比如 http_requests_total{method="POST", status="200“} 代表 POST 响应结果为 200 的请求总数。Prometheus 不仅能很容易地通过增加 label 为一个 metric 增加描述维度,而且还很方便的支持数据查询时的过滤和聚合,比如需要获取所有响应为 200 的请求的总数时,只需要指定 http_request_total{status="200"}。
Prometheus 将 metric 随时间流逝产生的一系列值称之为 time series(时间序列)。某个确定的时间点的数据被称为 sample(样本),它由一个 float64 的浮点值和以毫秒为单位的时间戳组成。
样本:在时间序列中的每一个点称为一个样本(sample),样本由以下三部分组成:
- 指标(
metric):指标名称和描述当前样本特征的 labelsets; - 时间戳(
timestamp):一个精确到毫秒的时间戳; - 样本值(
value): 一个 folat64 的浮点型数据表示当前样本的值。
如果metric不带时间戳,那么时间戳就是采集样本时的时间
这里重点写一下指标:
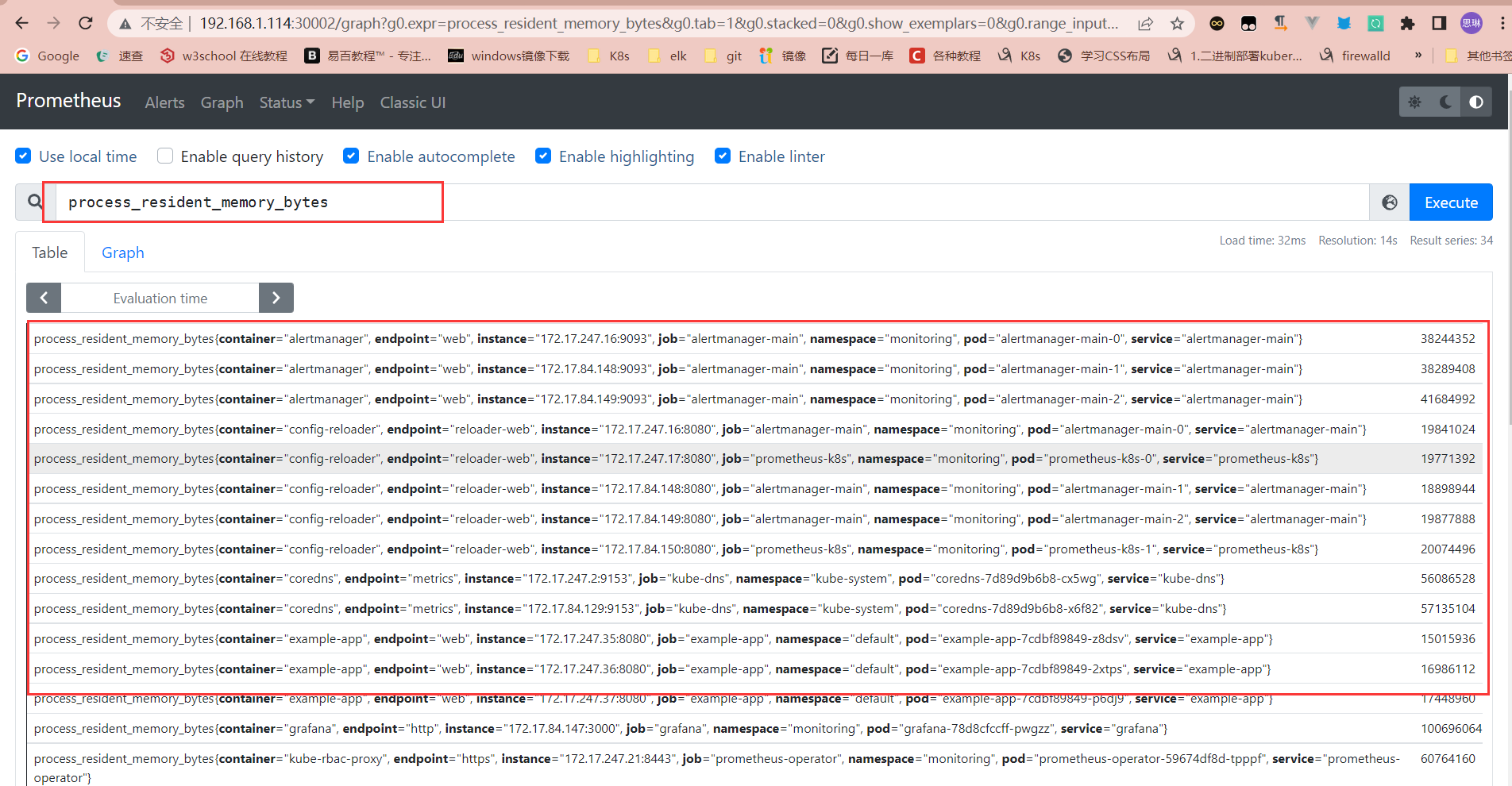
指标的名字自然不用说,而label是区分各个指标的关键,例如:在k8s中部署的一个example实例,里面可以获取metric,其中有一个metirc是这样的process_resident_memory_bytes
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 1.744896e+07可以看到,这个指标名没有任何的label,而我们一共部署了三个样本,所以prometheus想要区分这些metric,肯定会给其做一些操作。而这些操作就是向这些数据加一些标签。
可以看到,我们单纯只用这个名字搜索,无法搜索到我们想要的内容
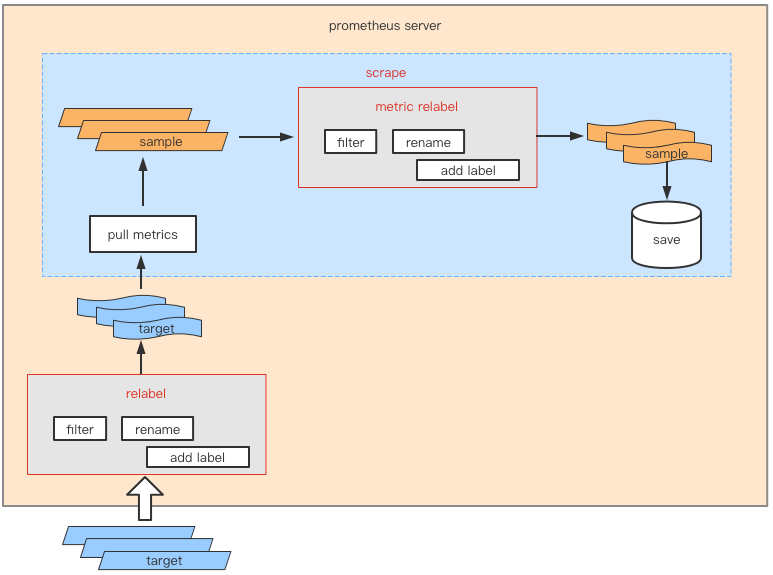
可以看到,在target采集之前,prometheus会将数据经过一次relabel,这次relabel配置,是在prometheus配置文件的
scrape_configs.[].relabel_configs中。而在存入数据库的前一步也有一个relabel的过程,它的书写过程和上面的relabel一样,这次relabel的消费十分大,毕竟数据已经采集起来了,而metirc relabel对应着scrape_configs.[].metric_relabel_configs下的配置