关键字
关键字:
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
保留字:
Constants: true false iota nil
Types: int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
Functions: make len cap new append copy close delete
complex real imag
panic recover变量
- 函数外的每个语句都必须以关键字开始(var、const、func等)
:=不能使用在函数外。_多用于占位,表示忽略值。
标准声明
var 变量名 变量类型批量声明
var (
a string
b int
c bool
d float32
)变量初始化
//标准表达式
var 变量名 类型 = 表达式
//例子
var name string = "Q1mi"
var age int = 18
//一次初始化多个
var name, age = "Q1mi", 20我们有时候不需要进行声明类型是什么,go会自动推断变量的类型
短变量声明
只可以在函数内部使用,在函数外是不可以使用的
package main
import (
"fmt"
)
// 全局变量m
var m = 100
func main() {
n := 10
m := 200 // 此处声明局部变量m
fmt.Println(m, n)
}匿名变量
在执行函数时,有时候会返回多个值,如果有的值我们不想要,可以将其赋值给匿名变量(anonymous variable),也就是
_
func foo() (int, string) {
return 10, "Q1mi"
}
func main() {
x, _ := foo()
_, y := foo()
fmt.Println("x=", x)
fmt.Println("y=", y)
}常量
常量在定义的时候必须赋值
const pi = 3.1415
const e = 2.7182声明了
pi和e这两个常量之后,在整个程序运行期间它们的值都不能再发生变化了。
多个常量也可以一起声明:
const (
pi = 3.1415
e = 2.7182
)const同时声明多个常量时,如果省略了值则表示和上面一行的值相同。 例如:
const (
n1 = 100
n2
n3
)上面示例中,常量
n1、n2、n3的值都是100。
iota
iota是go语言的常量计数器,只能在常量的表达式中使用。
iota在const关键字出现时将被重置为0。const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。
举个例子:
const (
n1 = iota //0
n2 //1
n3 //2
n4 //3
)几个常见的iota示例:
使用_跳过某些值
const (
n1 = iota //0
n2 //1
_
n4 //3
)iota声明中间插队,如果n3后面没有声明iota,那么n3,n4的值就n2相同
const (
n1 = iota //0
n2 = 100 //100
n3 = iota //2
n4 //3
)
const n5 = iota //0定义数量级 (这里的<<表示左移操作,1<<10表示将1的二进制表示向左移10位,也就是由1变成了10000000000,也就是十进制的1024。同理2<<2表示将2的二进制表示向左移2位,也就是由10变成了1000,也就是十进制的8。)
const (
_ = iota
KB = 1 << (10 * iota)
MB = 1 << (10 * iota)
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
)多个iota定义在一行
const (
a, b = iota + 1, iota + 2 //1,2
c, d //2,3
e, f //3,4
)循环语句
if else(分支结构)
if条件判断基本写法
Go语言中if条件判断的格式如下:
if 表达式1 {
分支1
} else if 表达式2 {
分支2
} else{
分支3
}Go语言规定与
if匹配的左括号{必须与if和表达式放在同一行,{放在其他位置会触发编译错误。 同理,与else匹配的{也必须与else写在同一行,else也必须与上一个if或else if右边的大括号在同一行。
if条件判断特殊写法
if条件判断还有一种特殊的写法,可以在 if 表达式之前添加一个执行语句,再根据变量值进行判断,举个例子:
func ifDemo2() {
if score := 65; score >= 90 {
fmt.Println("A")
} else if score > 75 {
fmt.Println("B")
} else {
fmt.Println("C")
}
}for(循环结构)
Go 语言中的所有循环类型均可以使用for关键字来完成。
for循环的基本格式如下:
for 初始语句;条件表达式;结束语句{
循环体语句
}for循环的初始语句可以被忽略,但是初始语句后的分号必须要写,例如:
func forDemo2() {
i := 0
for ; i < 10; i++ {
fmt.Println(i)
}
}for循环的初始语句和结束语句都可以省略,例如:
func forDemo3() {
i := 0
for i < 10 {
fmt.Println(i)
i++
}
}这种写法类似于其他编程语言中的while,在while后添加一个条件表达式,满足条件表达式时持续循环,否则结束循环。
无限循环
for {
循环体语句
}for循环可以通过break、goto、return、panic语句强制退出循环。
for range(键值循环)
Go语言中可以使用for range遍历数组、切片、字符串、map 及通道(channel)。 通过for range遍历的返回值有以下规律:
- 数组、切片、字符串返回索引和值。
- map返回键和值。
- 通道(channel)只返回通道内的值。
switch case
使用switch语句可方便地对大量的值进行条件判断。
func switchDemo1() {
finger := 3
switch finger {
case 1:
fmt.Println("大拇指")
case 2:
fmt.Println("食指")
case 3:
fmt.Println("中指")
case 4:
fmt.Println("无名指")
case 5:
fmt.Println("小拇指")
default:
fmt.Println("无效的输入!")
}
}Go语言规定每个switch只能有一个default分支。
一个分支可以有多个值,多个case值中间使用英文逗号分隔。
func testSwitch3() {
switch n := 7; n {
case 1, 3, 5, 7, 9:
fmt.Println("奇数")
case 2, 4, 6, 8:
fmt.Println("偶数")
default:
fmt.Println(n)
}
}分支还可以使用表达式,这时候switch语句后面不需要再跟判断变量。例如:
func switchDemo4() {
age := 30
switch {
case age < 25:
fmt.Println("好好学习吧")
case age > 25 && age < 35:
fmt.Println("好好工作吧")
case age > 60:
fmt.Println("好好享受吧")
default:
fmt.Println("活着真好")
}
}fallthrough语法可以执行满足条件的case的下一个case,是为了兼容C语言中的case设计的。
func switchDemo5() {
s := "a"
switch {
case s == "a":
fmt.Println("a")
fallthrough
case s == "b":
fmt.Println("b")
case s == "c":
fmt.Println("c")
default:
fmt.Println("...")
}
}输出:
a
bgoto(跳转到指定标签)
goto语句通过标签进行代码间的无条件跳转。goto语句可以在快速跳出循环、避免重复退出上有一定的帮助。Go语言中使用goto语句能简化一些代码的实现过程。 例如双层嵌套的for循环要退出时:
func gotoDemo1() {
var breakFlag bool
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
// 设置退出标签
breakFlag = true
break
}
fmt.Printf("%v-%v\n", i, j)
}
// 外层for循环判断
if breakFlag {
break
}
}
}使用goto语句能简化代码:
func gotoDemo2() {
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
// 设置退出标签
goto breakTag
}
fmt.Printf("%v-%v\n", i, j)
}
}
return
// 标签
breakTag:
fmt.Println("结束for循环")
}break(跳出循环)
break语句可以结束for、switch和select的代码块。
break语句还可以在语句后面添加标签,表示退出某个标签对应的代码块,标签要求必须定义在对应的for、switch和 select的代码块上。 举个例子:
func breakDemo1() {
BREAKDEMO1:
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
break BREAKDEMO1
}
fmt.Printf("%v-%v\n", i, j)
}
}
fmt.Println("...")
}结果:
直接退出最外层循环
0-0
0-1
...continue(继续下次循环)
continue语句可以结束当前循环,开始下一次的循环迭代过程,仅限在for循环内使用。
在 continue语句后添加标签时,表示开始标签对应的循环。例如:
func continueDemo() {
forloop1:
for i := 0; i < 5; i++ {
// forloop2:
for j := 0; j < 5; j++ {
if i == 2 && j == 2 {
continue forloop1
}
fmt.Printf("%v-%v\n", i, j)
}
}
}如果不写continue后面的tag,那么之后跳过内层循环,感觉使用continue的tag之后,直接跳转到了下一次的外层循环
数组与切片
Array(数组)
数组是值类型
数组是值类型,赋值和传参会复制整个数组。因此改变副本的值,不会改变本身的值。
注意:
- 数组支持 “==“、”!=” 操作符,只支持长度相同并且类型相同的元素
[n]*T表示指针数组,*[n]T表示数组指针 。
数组定义:
var 数组变量名 [元素数量]T比如:var a [5]int, 数组的长度必须是常量,并且长度是数组类型的一部分。一旦定义,长度不能变。 [5]int和[10]int是不同的类型。
数组的初始化
数组的初始化也有很多方式。
方法一
一般情况下我们可以让编译器根据初始值的个数自行推断数组的长度,例如:
func main() {
var testArray [3]int
var numArray = [...]int{1, 2}
var cityArray = [...]string{"北京", "上海", "深圳"}
fmt.Println(testArray) //[0 0 0]
fmt.Println(numArray) //[1 2]
fmt.Printf("type of numArray:%T\n", numArray) //type of numArray:[2]int
fmt.Println(cityArray) //[北京 上海 深圳]
fmt.Printf("type of cityArray:%T\n", cityArray) //type of cityArray:[3]string
}方法二
我们还可以使用指定索引值的方式来初始化数组,例如:
func main() {
a := [...]int{1: 1, 3: 5}
fmt.Println(a) // [0 1 0 5]
fmt.Printf("type of a:%T\n", a) //type of a:[4]int
}数组的遍历
遍历数组a有以下两种方法:
func main() {
var a = [...]string{"北京", "上海", "深圳"}
// 方法1:for循环遍历
for i := 0; i < len(a); i++ {
fmt.Println(a[i])
}
// 方法2:for range遍历
for index, value := range a {
fmt.Println(index, value)
}
}多维数组
Go语言是支持多维数组的,我们这里以二维数组为例(数组中又嵌套数组)。
二维数组的定义
func main() {
a := [3][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
fmt.Println(a) //[[北京 上海] [广州 深圳] [成都 重庆]]
fmt.Println(a[2][1]) //支持索引取值:重庆
}二维数组的遍历
func main() {
a := [3][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
for _, v1 := range a {
for _, v2 := range v1 {
fmt.Printf("%s\t", v2)
}
fmt.Println()
}
}输出:
北京 上海
广州 深圳
成都 重庆注意: 多维数组只有第一层可以使用...来让编译器推导数组长度。例如:
//支持的写法
a := [...][2]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}
//不支持多维数组的内层使用...
b := [3][...]string{
{"北京", "上海"},
{"广州", "深圳"},
{"成都", "重庆"},
}切片
切片(Slice)是一个拥有相同类型元素的可变长度的序列。它是基于数组类型做的一层封装。它非常灵活,支持自动扩容。
切片是一个引用类型,它的内部结构包含地址、长度和容量。切片一般用于快速地操作一块数据集合。
切片的定义
声明切片类型的基本语法如下:
var name []T其中,
- name:表示变量名
- T:表示切片中的元素类型
举个例子:
func main() {
// 声明切片类型
var a []string //声明一个字符串切片
var b = []int{} //声明一个整型切片并初始化
var c = []bool{false, true} //声明一个布尔切片并初始化
var d = []bool{false, true} //声明一个布尔切片并初始化
fmt.Println(a) //[]
fmt.Println(b) //[]
fmt.Println(c) //[false true]
fmt.Println(a == nil) //true
fmt.Println(b == nil) //false
fmt.Println(c == nil) //false
// fmt.Println(c == d) //切片是引用类型,不支持直接比较,只能和nil比较
}切片的长度和容量
切片拥有自己的长度和容量,我们可以通过使用内置的len()函数求长度,使用内置的cap()函数求切片的容量。
切片表达式
切片表达式从字符串、数组、指向数组或切片的指针构造子字符串或切片。它有两种变体:一种指定low和high两个索引界限值的简单的形式,另一种是除了low和high索引界限值外还指定容量的完整的形式。
简单切片表达式
切片的底层就是一个数组,所以我们可以基于数组通过切片表达式得到切片。 切片表达式中的low和high表示一个索引范围(左包含,右不包含),也就是下面代码中从数组a中选出1<=索引值<4的元素组成切片s,得到的切片长度=high-low,容量等于得到的切片的底层数组的容量。
func main() {
a := [5]int{1, 2, 3, 4, 5}
s := a[1:3] // s := a[low:high]
fmt.Printf("s:%v len(s):%v cap(s):%v\n", s, len(s), cap(s))
}输出:
s:[2 3] len(s):2 cap(s):4为了方便起见,可以省略切片表达式中的任何索引。省略了low则默认为0;省略了high则默认为切片操作数的长度:
a[2:] // 等同于 a[2:len(a)]
a[:3] // 等同于 a[0:3]
a[:] // 等同于 a[0:len(a)]注意:
对于数组或字符串,如果0 <= low <= high <= len(a),则索引合法,否则就会索引越界(out of range)。
对切片再执行切片表达式时(切片再切片),high的上限边界是切片的容量cap(a),而不是长度。常量索引必须是非负的,并且可以用int类型的值表示;对于数组或常量字符串,常量索引也必须在有效范围内。如果low和high两个指标都是常数,它们必须满足low <= high。如果索引在运行时超出范围,就会发生运行时panic。
func main() {
a := [5]int{1, 2, 3, 4, 5}
s := a[1:3] // s := a[low:high]
fmt.Printf("s:%v len(s):%v cap(s):%v\n", s, len(s), cap(s))
s2 := s[3:4] // 索引的上限是cap(s)而不是len(s)
fmt.Printf("s2:%v len(s2):%v cap(s2):%v\n", s2, len(s2), cap(s2))
}输出:
s:[2 3] len(s):2 cap(s):4
s2:[5] len(s2):1 cap(s2):1完整切片表达式
对于数组,指向数组的指针,或切片a(注意不能是字符串)支持完整切片表达式:
a[low : high : max]上面的代码会构造与简单切片表达式a[low: high]相同类型、相同长度和元素的切片。另外,它会将得到的结果切片的容量设置为max-low。在完整切片表达式中只有第一个索引值(low)可以省略;它默认为0。
func main() {
a := [5]int{1, 2, 3, 4, 5}
t := a[1:3:5]
fmt.Printf("t:%v len(t):%v cap(t):%v\n", t, len(t), cap(t))
}输出结果:
t:[2 3] len(t):2 cap(t):4完整切片表达式需要满足的条件是0 <= low <= high <= max <= cap(a),其他条件和简单切片表达式相同。
使用make()函数构造切片
我们上面都是基于数组来创建的切片,如果需要动态的创建一个切片,我们就需要使用内置的make()函数,格式如下:
make([]T, size, cap)其中:
- T:切片的元素类型
- size:切片中元素的数量
- cap:切片的容量
举个例子:
func main() {
a := make([]int, 2, 10)
fmt.Println(a) //[0 0]
fmt.Println(len(a)) //2
fmt.Println(cap(a)) //10
}上面代码中a的内部存储空间已经分配了10个,但实际上只用了2个。 容量并不会影响当前元素的个数,所以len(a)返回2,cap(a)则返回该切片的容量。
切片的本质
切片的本质就是对底层数组的封装,它包含了三个信息:底层数组的指针、切片的长度(len)和切片的容量(cap)。
举个例子,现在有一个数组a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片s1 := a[:5],相应示意图如下。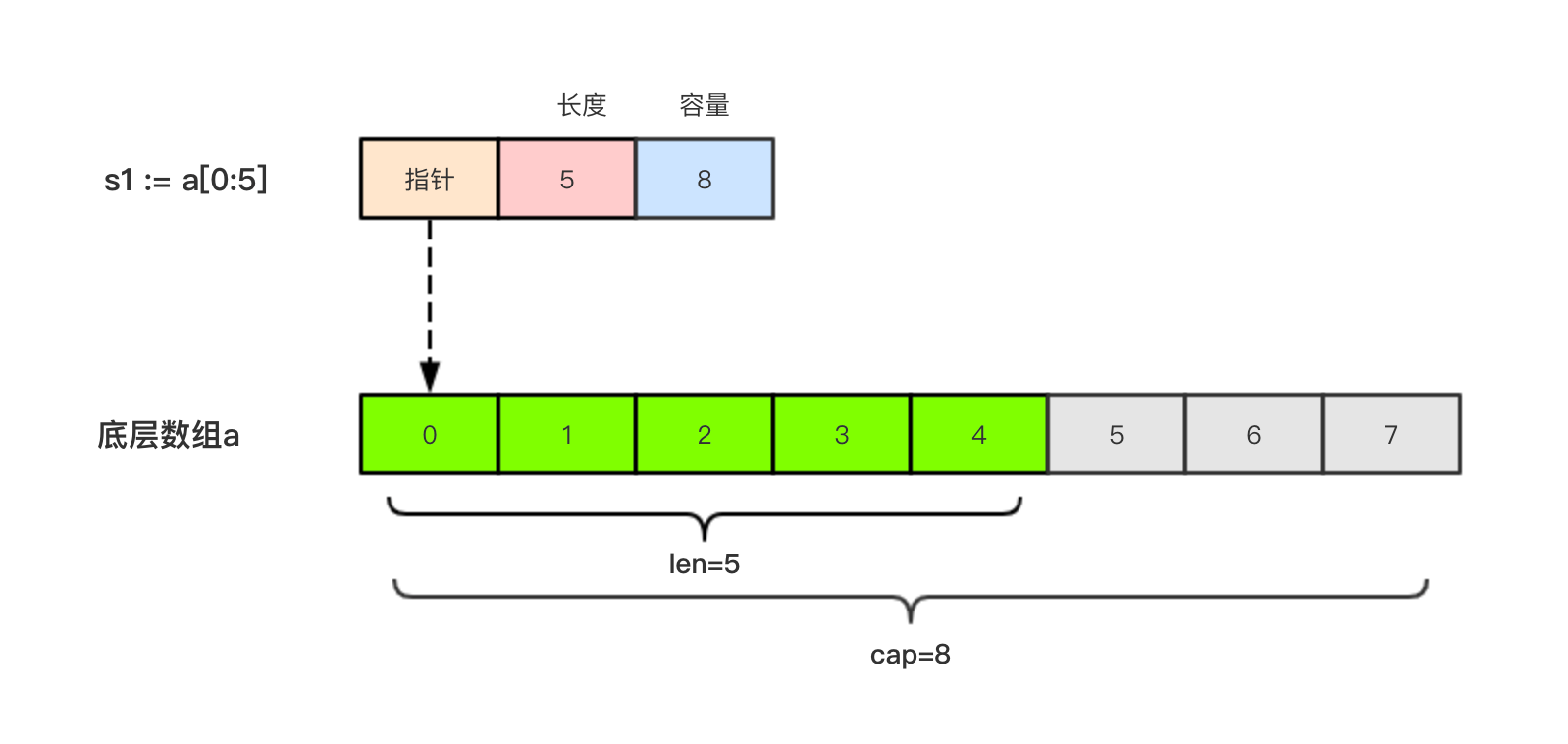 切片
切片s2 := a[3:6],相应示意图如下: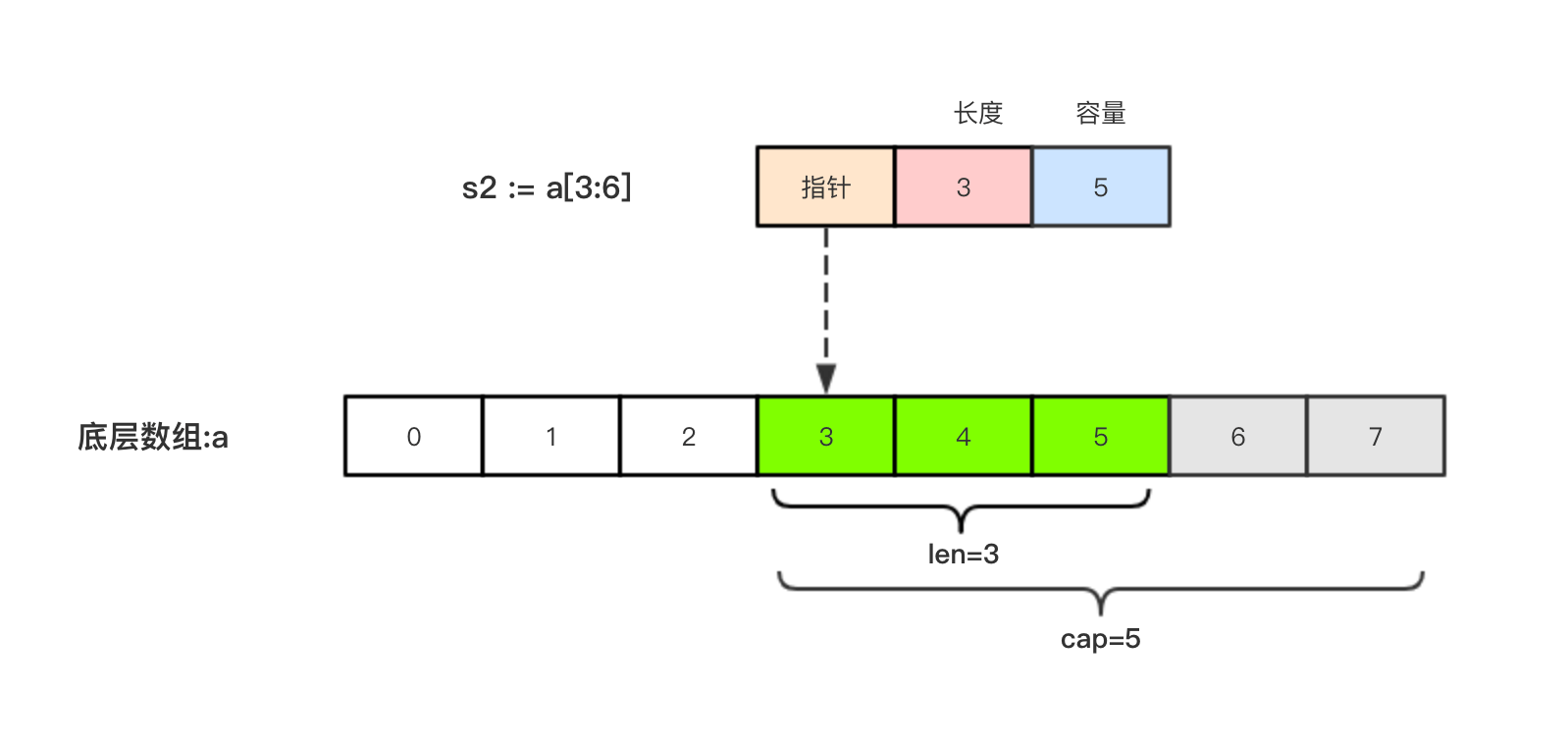
判断切片是否为空
要检查切片是否为空,请始终使用len(s) == 0来判断,而不应该使用s == nil来判断。
切片不能直接比较
切片之间是不能比较的,我们不能使用==操作符来判断两个切片是否含有全部相等元素。 切片唯一合法的比较操作是和nil比较。 一个nil值的切片并没有底层数组,一个nil值的切片的长度和容量都是0。但是我们不能说一个长度和容量都是0的切片一定是nil,例如下面的示例:
var s1 []int //len(s1)=0;cap(s1)=0;s1==nil
s2 := []int{} //len(s2)=0;cap(s2)=0;s2!=nil
s3 := make([]int, 0) //len(s3)=0;cap(s3)=0;s3!=nil所以要判断一个切片是否是空的,要是用len(s) == 0来判断,不应该使用s == nil来判断。
切片的赋值拷贝
下面的代码中演示了拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容,这点需要特别注意。
func main() {
s1 := make([]int, 3) //[0 0 0]
s2 := s1 //将s1直接赋值给s2,s1和s2共用一个底层数组
s2[0] = 100
fmt.Println(s1) //[100 0 0]
fmt.Println(s2) //[100 0 0]
}切片遍历
切片的遍历方式和数组是一致的,支持索引遍历和for range遍历。
func main() {
s := []int{1, 3, 5}
for i := 0; i < len(s); i++ {
fmt.Println(i, s[i])
}
for index, value := range s {
fmt.Println(index, value)
}
}append()方法为切片添加元素
Go语言的内建函数append()可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)。
func main(){
var s []int
s = append(s, 1) // [1]
s = append(s, 2, 3, 4) // [1 2 3 4]
s2 := []int{5, 6, 7}
s = append(s, s2...) // [1 2 3 4 5 6 7]
}**注意:**通过var声明的零值切片可以在append()函数直接使用,无需初始化。
var s []int
s = append(s, 1, 2, 3)没有必要像下面的代码一样初始化一个切片再传入append()函数使用,
s := []int{} // 没有必要初始化
s = append(s, 1, 2, 3)
var s = make([]int) // 没有必要初始化
s = append(s, 1, 2, 3)每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。
举个例子:
func main() {
//append()添加元素和切片扩容
var numSlice []int
for i := 0; i < 10; i++ {
numSlice = append(numSlice, i)
fmt.Printf("%v len:%d cap:%d ptr:%p\n", numSlice, len(numSlice), cap(numSlice), numSlice)
}
}输出:
[0] len:1 cap:1 ptr:0xc0000a8000
[0 1] len:2 cap:2 ptr:0xc0000a8040
[0 1 2] len:3 cap:4 ptr:0xc0000b2020
[0 1 2 3] len:4 cap:4 ptr:0xc0000b2020
[0 1 2 3 4] len:5 cap:8 ptr:0xc0000b6000
[0 1 2 3 4 5] len:6 cap:8 ptr:0xc0000b6000
[0 1 2 3 4 5 6] len:7 cap:8 ptr:0xc0000b6000
[0 1 2 3 4 5 6 7] len:8 cap:8 ptr:0xc0000b6000
[0 1 2 3 4 5 6 7 8] len:9 cap:16 ptr:0xc0000b8000
[0 1 2 3 4 5 6 7 8 9] len:10 cap:16 ptr:0xc0000b8000从上面的结果可以看出:
append()函数将元素追加到切片的最后并返回该切片。- 切片numSlice的容量按照1,2,4,8,16这样的规则自动进行扩容,每次扩容后都是扩容前的2倍。
append()函数还支持一次性追加多个元素。 例如:
var citySlice []string
// 追加一个元素
citySlice = append(citySlice, "北京")
// 追加多个元素
citySlice = append(citySlice, "上海", "广州", "深圳")
// 追加切片
a := []string{"成都", "重庆"}
citySlice = append(citySlice, a...)
fmt.Println(citySlice) //[北京 上海 广州 深圳 成都 重庆]切片的扩容策略
可以通过查看$GOROOT/src/runtime/slice.go源码,其中扩容相关代码如下:
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}从上面的代码可以看出以下内容:
- 首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
- 否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap),
- 否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
- 如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
需要注意的是,切片扩容还会根据切片中元素的类型不同而做不同的处理,比如int和string类型的处理方式就不一样。
使用copy()函数复制切片
首先我们来看一个问题:
func main() {
a := []int{1, 2, 3, 4, 5}
b := a
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(b) //[1 2 3 4 5]
b[0] = 1000
fmt.Println(a) //[1000 2 3 4 5]
fmt.Println(b) //[1000 2 3 4 5]
}由于切片是引用类型,所以a和b其实都指向了同一块内存地址。修改b的同时a的值也会发生变化。
Go语言内建的copy()函数可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数的使用格式如下:
copy(destSlice, srcSlice []T)其中:
- srcSlice: 数据来源切片
- destSlice: 目标切片
举个例子:
func main() {
// copy()复制切片
a := []int{1, 2, 3, 4, 5}
c := make([]int, 5, 5)
copy(c, a) //使用copy()函数将切片a中的元素复制到切片c
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1 2 3 4 5]
c[0] = 1000
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1000 2 3 4 5]
}从切片中删除元素
Go语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素。 代码如下:
func main() {
// 从切片中删除元素
a := []int{30, 31, 32, 33, 34, 35, 36, 37}
// 要删除索引为2的元素
a = append(a[:2], a[3:]...)
fmt.Println(a) //[30 31 33 34 35 36 37]
}总结一下就是:要从切片a中删除索引为index的元素,操作方法是a = append(a[:index], a[index+1:]...)
map
- Map的Key必须是可比较类型
map定义
Go语言中 map的定义语法如下:
map[KeyType]ValueType其中,
- KeyType:表示键的类型。
- ValueType:表示键对应的值的类型。
map类型的变量默认初始值为nil,需要使用make()函数来分配内存。语法为:
make(map[KeyType]ValueType, [cap])其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量,设置大小也可以进行扩容
map基本使用
map中的数据都是成对出现的,map的基本使用示例代码如下:
func main() {
scoreMap := make(map[string]int, 8)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
fmt.Println(scoreMap)
fmt.Println(scoreMap["小明"])
fmt.Printf("type of a:%T\n", scoreMap)
}输出:
map[小明:100 张三:90]
100
type of a:map[string]intmap也支持在声明的时候填充元素,例如:
func main() {
userInfo := map[string]string{
"username": "沙河小王子",
"password": "123456",
}
fmt.Println(userInfo) //
}判断某个键是否存在
Go语言中有个判断map中键是否存在的特殊写法,格式如下:
value, ok := map[key]举个例子:
func main() {
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
// 如果key存在ok为true,v为对应的值;不存在ok为false,v为值类型的零值
v, ok := scoreMap["张三"]
if ok {
fmt.Println(v)
} else {
fmt.Println("查无此人")
}
}map的遍历
Go语言中使用for range遍历map。
func main() {
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
scoreMap["娜扎"] = 60
for k, v := range scoreMap {
fmt.Println(k, v)
}
}但我们只想遍历key的时候,可以按下面的写法:
func main() {
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
scoreMap["娜扎"] = 60
for k := range scoreMap {
fmt.Println(k)
}
}注意: 遍历map时的元素顺序与添加键值对的顺序无关。
使用delete()函数删除键值对
使用delete()内建函数从map中删除一组键值对,delete()函数的格式如下:
delete(map, key)其中,
- map:表示要删除键值对的map
- key:表示要删除的键值对的键
示例代码如下:
func main(){
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
scoreMap["娜扎"] = 60
delete(scoreMap, "小明")//将小明:100从map中删除
for k,v := range scoreMap{
fmt.Println(k, v)
}
}按照指定顺序遍历map
func main() {
rand.Seed(time.Now().UnixNano()) //初始化随机数种子
var scoreMap = make(map[string]int, 200)
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu%02d", i) //生成stu开头的字符串
value := rand.Intn(100) //生成0~99的随机整数
scoreMap[key] = value
}
//取出map中的所有key存入切片keys
var keys = make([]string, 0, 200)
for key := range scoreMap {
keys = append(keys, key)
}
//对切片进行排序
sort.Strings(keys)
//按照排序后的key遍历map
for _, key := range keys {
fmt.Println(key, scoreMap[key])
}
}元素为map类型的切片
下面的代码演示了切片中的元素为map类型时的操作:
func main() {
var mapSlice = make([]map[string]string, 3)
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
fmt.Println("after init")
// 对切片中的map元素进行初始化
mapSlice[0] = make(map[string]string, 10)
mapSlice[0]["name"] = "小王子"
mapSlice[0]["password"] = "123456"
mapSlice[0]["address"] = "沙河"
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
}值为切片类型的map
下面的代码演示了map中值为切片类型的操作:
func main() {
var sliceMap = make(map[string][]string, 3)
fmt.Println(sliceMap)
fmt.Println("after init")
key := "中国"
value, ok := sliceMap[key]
if !ok {
value = make([]string, 0, 2)
}
value = append(value, "北京", "上海")
sliceMap[key] = value
fmt.Println(sliceMap)
}
value, ok := sliceMap[key],要是map里面有元素返回对应的元素和true,不然就返回nil和false
函数的定义
返回值
有一个返回值
func sum(a, b int) (ret int) {
ret = a + b
return ret
}
func sum2(a, b int) (int) {
ret := a + b
return ret
}
func sum3(a int, b int) int {
# 当返回多个参数时,必须携带()
return a + b
}多个返回值,且在return中指定返回的内容
func return_one() (name string, age int) {
name = "tom"
age = 20
return name, age
}多个返回值,返回值名称没有被使用
func return_two() (name string, age int) {
name = "tom"
age = 20
return // 等价于 return name, age
}return覆盖命名返回值,返回值名称没有被使用
func return_cover() (name string, age int) {
n := "你好"
a := 20
return n, a
}